defcenterPoint(point_set): # 获取点的维度 dim = len(point_set[0]) res = [] for i inrange(dim): res.append(0) for i inrange(dim): for j in point_set: res[i] += j[i] for i inrange(dim): res[i] = res[i] / len(point_set) # 每个维度依次求平均,重心求法 return res
defmyKMeans(n_clusters): key_index = random.sample(range(1, len(data)), n_clusters) # key_index = [20, 80, 140] # 这里并没有选择随机,而是选择了三个直观符合分类分布的三个点为初始值 is_change = True key_point = [] group = [[] for _ inrange(n_clusters)] cmp = 0 # 初始化:以n个关键点分组 for i inrange(n_clusters): group[i].append(data[key_index[i]]) # i同时对应group与key key_point.append(data[key_index[i]]) # 迭代器 while is_change: # 遍历所有点 for i inrange(len(data)): # 与n个目标点比较 tmp_dis = [] for j inrange(n_clusters): tmp_dis.append(eucliDist(key_point[j], data[i])) min_index = np.argmin(np.array(tmp_dis)) group[min_index].append(data[i])
# 计算每组的中心对象 tmp_key_point = [] for i inrange(n_clusters): new_center = centerPoint(group[i]) tmp_key_point.append(new_center) cmp += float(eucliDist(new_center, key_point[i])) # 比较中心点与目标点差异 if cmp < 0.00002: is_change = False key_point = tmp_key_point else: is_change = True key_point = tmp_key_point cmp = 0 for i inrange(n_clusters): group[i][0] = key_point[i] predicted = [] for d in data: for j inrange(n_clusters): if d in group[j]: predicted.append(j) break return predicted, group, key_point
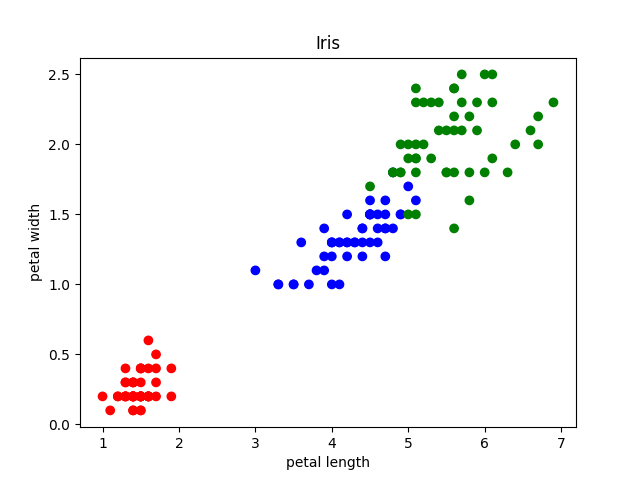
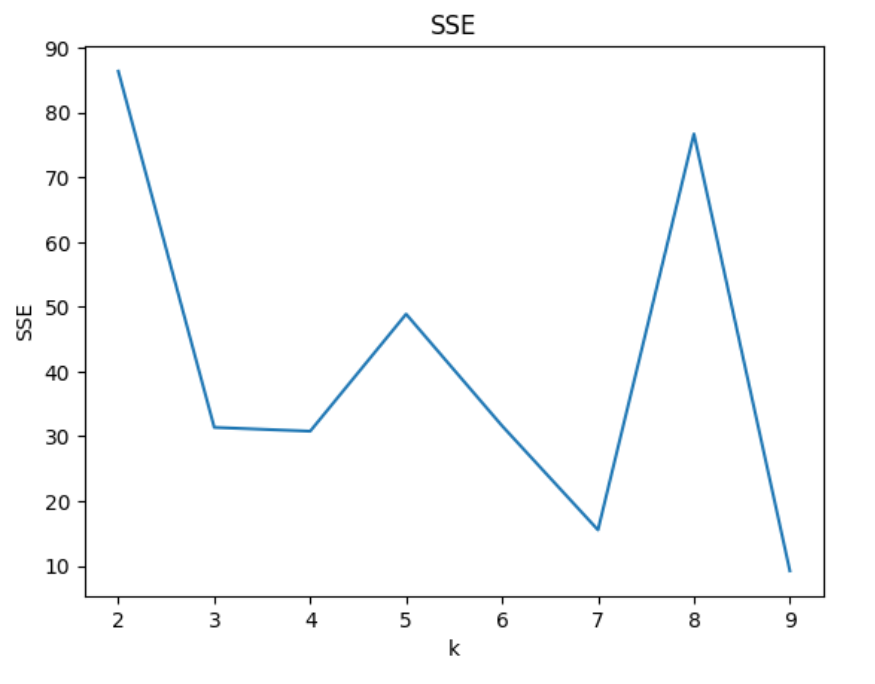
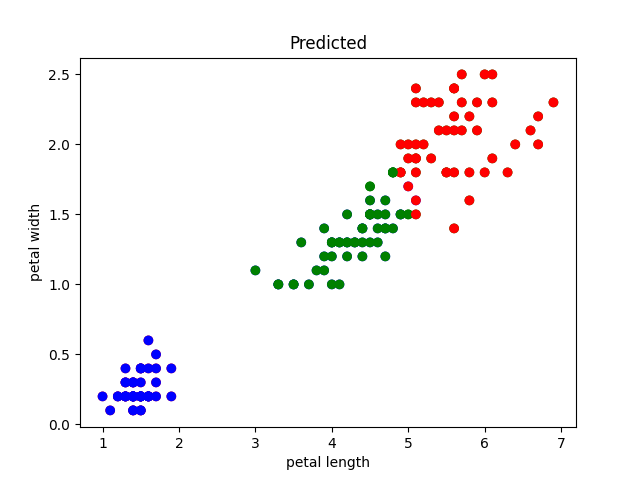
接收结果并且数据可视化结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
n = 3 p, g, k = myKMeans(n) colors_p = [] for i in p: if i == 0: colors_p.append("red") elif i == 1: colors_p.append("blue") else: colors_p.append("green")