Introduction
强化学习人类反馈(Reinforcement Learning from Human Feedback, RLHF)是一种通过结合强化学习和人类反馈来优化模型性能的方法。RLHF特别适用于那些主观性强、没有明确目标的任务,例如生成文本摘要、回答开放性问题等。

RLHF Process
Step 1: 创建偏好数据集(Preference Dataset)
- 给LLM(大型语言模型)一个文本,让基座模型生成两个摘要(Summary1和Summary2)。
- 人工标注:对于特定输入,给出两个摘要,并标注哪个更好。注意这里不能使用标量(scaler)评分,而是记录哪个摘要更好,即偏好数据集(Preference Dataset)。
监督微调(Supervised Fine Tuning)
- 输入:文本 → 输出:摘要
强化学习人类反馈(RLHF)
- 输入:文本 → 输出:摘要1,摘要2,人类偏好
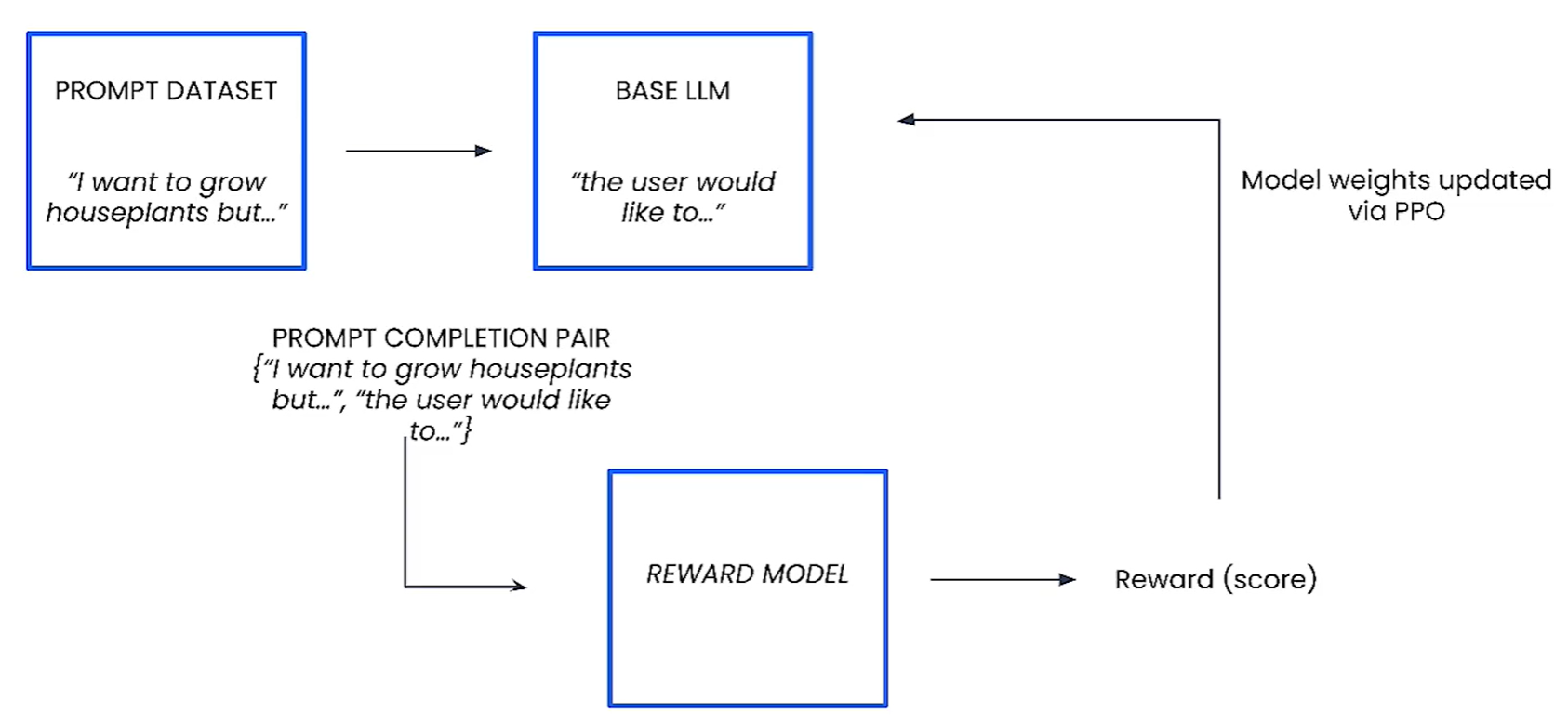
Step 2: 奖励模型(Reward Model)
- {Prompt, Completion} → 奖励模型(Reward Model)(推理)→ 标量(Scaler),表示这个完成度如何
- 奖励模型的推理本质上是一个回归任务,其训练目标是:
- {Prompt, Winning Candidate, Losing Candidate}
- 目标是最大化胜出摘要与失败摘要之间的评分差异
Step 3: 在RL循环中使用奖励模型微调LLM
调整基座模型的输出以最大化奖励。
引入一个新的提示数据集(Prompt Dataset),仅为提示数据集。
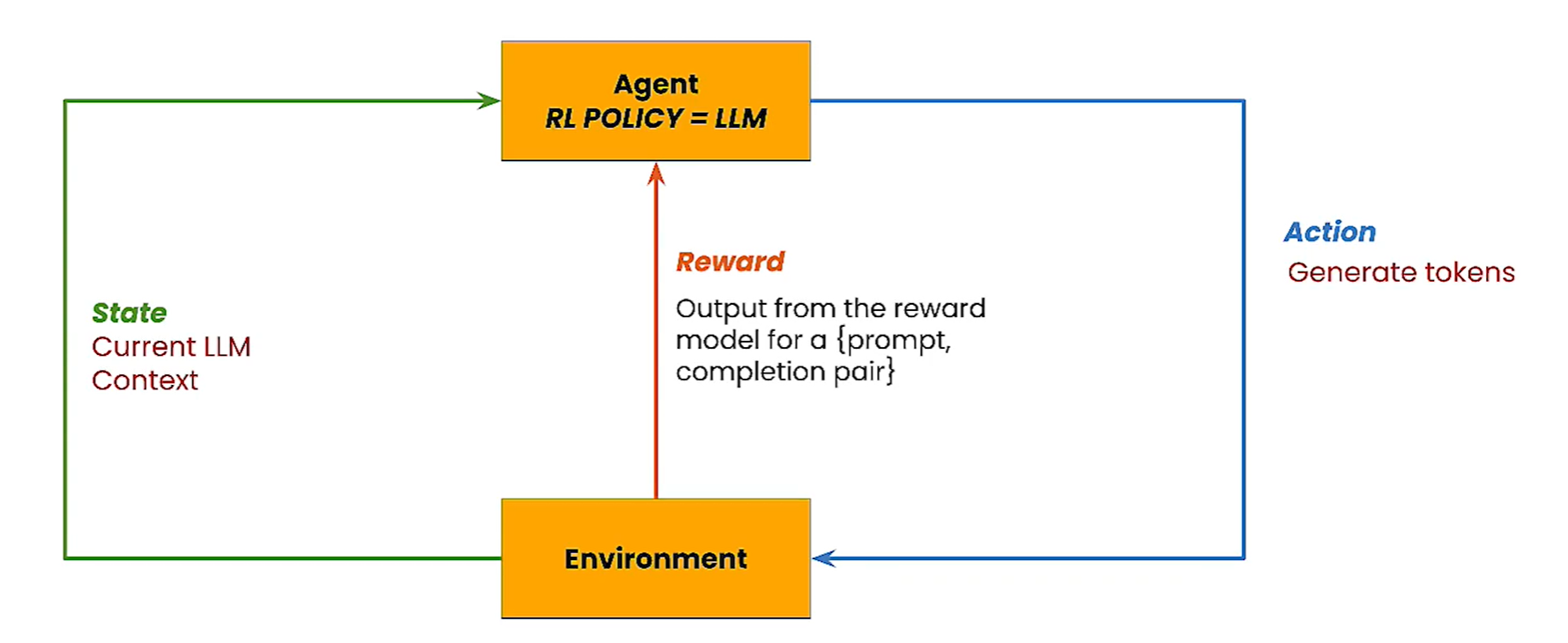
强化学习(Reinforcement Learning)适用于复杂但开放的任务训练方法,Agent通过与环境的交互来解决任务。Agent通过行为作用在环境中,环境更新Agent的状态并给出奖励(正向或负向)。通过重复这个过程,Agent使用一个函数记录学习结果,函数以当前状态为输入,输出最合适的行为(Policy)。
RLHF在LLM中的应用
- Agent:初始策略为基座LLM生成策略,初始状态为文本信息(Prompt)。
- 每次LLM生成tokens完成输出后,都会从奖励模型得到反馈分数:
- {Prompt, Completion} → Score
- 学习目标是获得最高分数的生成策略(Policy),学习方法为近端策略优化(Proximal Policy Optimization, PPO)。
代码实践
微调方法
- 完全微调(Full Fine Tuning):更新所有权重。
- 参数高效微调(Parameter Efficient Tuning):只更新一部分参数,保留基座模型中的其他参数。
数据准备
偏好数据集:用于训练奖励模型
字典Key为
['input_text', 'candidate_0', 'candidate_1', 'choice']1
2
3
4
5
6{
'input_text': 'I live right next to a huge university, and have been applying for a variety of jobs with them through ... [summary]: ',
'candidate_0': ' When applying through a massive job portal, is just one HR person seeing ALL of them?',
'candidate_1': ' When applying to many jobs through a single university jobs portal, is just one HR person reading ALL my applications?',
'choice': 1
}我们可以看到input text末尾有
[summary]:标记,用于标记任务为summary任务Prompt数据集: 用于强化学习循环,在演示中仅有6条: 每个元素的格式为key+value:
1
{'input_text': "Nooooooo, I loved my health class! My teacher was amazing! Most days we just went outside and played and the facility allowed it because the health teacher's argument was that teens need to spend time outside everyday and he let us do that. The other days were spent inside with him teaching us how to live a healthy lifestyle. He had guest speakers come in and reach us about nutrition and our final was open book...if we even had a final.... [summary]: "}
RLHF Pipeline
RLHF Pipeline就是对下图流程的复现:

在实例中使用了谷歌云Pipeline平台,Pipeline由yaml文件定义,是一个完整了RLHF流程,我们需要导入平台并且准备好数据的路径。训练使用Llama2作为基座模型。
奖励模型训练步数设置
Reward_model_train_steps是训练奖励模型时使用的步数。这取决于首选项数据集的大小。我们建议模型应该在偏好数据集上训练20-30个epoch以获得最佳结果。
RLHF管道参数要求的是训练步数,而不是epoch数。下面是如何从epoch到训练步骤的示例,假设此管道的批处理大小固定为每批64个示例。
1 | # 训练数据大小 |
强化模型训练步数设置
Reinforcement learning train steps 参数是指在调优基础模型时要执行的强化学习步数。
- 训练步数取决于提示数据集的大小。通常,这个模型应该在提示数据集上训练大约10-20个epoch。
- Reward hacking:如果给予过多的训练步数,策略模型可能会找到一种方法来利用奖励,从而表现出不期望的行为。
强化模型的Epoch数通常为10-20,我们根据这个epoch计算总共的训练次数:
1 | # Prompt dataset size |
参数设置
根据上面计算的步长结果,填写整个任务流程中的超参数:
1 | # Completed values for the dictionary |
训练结果
- 训练奖励模型损失函数: 收敛较好

PPO训练曲线
KL Loss: KL (Kullback-Leibler) 散度(KL divergence)是一种衡量两个概率分布之间差异的非对称度量。在强化学习中,KL 散度通常用于衡量新策略与旧策略之间的差异,以确保策略更新不会过于激进,从而保持训练的稳定性。
初期快速上升:这是比较常见的现象,说明模型在初期调整过程中,策略变化较大,从而导致与旧策略之间的差异增大。
波动期:这段时间的波动可能是由于强化学习过程中的探索与利用权衡,模型在尝试不同策略以寻找最优解。这种波动也可能表明模型在调整过程中遇到了一些不稳定性。
稳定期:在训练的后期,KL损失趋于稳定,表明模型的策略更新幅度减小,策略逐渐稳定。这也说明模型已经找到了一个相对稳定的策略,不再进行大的调整。
两个Examples
| Input Text | Base LLM | Tuned LLM |
|---|---|---|
| Summarize in less than 50 words. Before anything, not a sad story or anything. My country’s equivalent to Valentine’s Day is coming and I had this pretty simple idea to surprise my girlfriend and it would involve giving her some roses. The thing is, although I know she would appreciate my intention in and of itself, I don’t know if she would like the actual flowers and such, so I wanted to find out if she likes roses and if she would like getting some, but without her realizing it so as not to spoil the surprise. Any ideas on how to get that information out of her? [summary]: | The author wants to surprise his girlfriend with roses on Valentine’s Day but he doesn’t know if she likes roses. He wants to find out without spoiling the surprise. | My country’s equivalent to Valentine’s Day is coming. Want to surprise my girlfriend with roses but don’t know if she would like getting some. Any ideas on how to get that information out of her without spoiling the surprise |
| Summarize in less than 50 words. Hello jobs, I graduated a few months ago and had no luck so far to get a job in marketing/sales. There’s a small local company (perhaps 30 employees) but they are actually pretty successful in what they’re doing (known worldwide). I checked their website and it’s awful. Looks like a website from the early 2000’s. So I guess they are not pretty good in (online-)marketing. I would like to do a cold application (not sure if they are looking for a marketing guy) but I had no luck with this kind of application in the past. That’s why I thought I try something different. I have good skills in Photoshop, InDesign and Illustrator. As a teenager I also built websites using HTML, so I thought I build a dummy website fitted to their company and attach some screenshots to my application. What do you think? I this a feasible idea or will they be offended? Thank you very much in advance. [summary]: | Graduated a few months ago, looking for a job in marketing/sales. Found a small local company that is successful but has an awful website. I want to apply for a marketing job but not sure if they are hiring. I thought of building a dummy website for them and attach some screenshots to my application. | Graduated a few months ago. No luck so far to get a job in marketing/sales. Thought to build a dummy website fitted to the company and attach some screenshots to my application. What do you think? |